SDK Intel® FPGA para OpenCL™ – Centro de suporte
Aviso de descontinuidade de produto
A Intel está descontinuando o Intel® FPGA SDK para OpenCL™, mais informações podem ser encontradas na notificação de descontinuação de produto (PDN2219).
A página de suporte do Intel® FPGA SDK para OpenCL fornece informações sobre como imitar, compilar e criar um perfil para o seu kernel. Há também diretrizes sobre como otimizar seu kernel, bem como informações sobre como depurar seu sistema durante a execução de aplicativos host. Esta página é organizada em duas grandes categorias baseadas na plataforma de desenvolvimento — desenvolvedor de kernel para FPGA e desenvolvedor de código de host para CPUs.
{kind=link}
Requisito de software
Você deve ter privilégios de administrador no sistema de desenvolvimento para instalar os pacotes e drivers necessários para o desenvolvimento de software do host.
O sistema host deve estar executando um dos seguintes sistemas operacionais Windows* e Linux* compatíveis, listados na página Suporte do sistema operacional .
Desenvolva seu aplicativo host para o Intel® FPGA SDK for OpenCL™ usando um dos seguintes ambientes de desenvolvimento:
Sistemas do so Windows
- SDK Intel FPGA para OpenCL
- Pacote de suporte para placas (BSP)
- Microsoft* Visual Studio Professional versão 2010 ou mais recente.
Sistemas do SO Linux
- SDK Intel FPGA para OpenCL
- BSP
- RPM (Gerenciador de pacotes RPM; gerenciador de pacotes Red Hat originalmente)
- Compilador C incluído com GCC
- Versão de comando Perl 5 ou mais recente
1. Desenvolvedor de Kernel
Interface de usuário SDK
Intel® FPGA SDK para OpenCL™ oferece dois modos de experiência de desenvolvimento para os usuários. Para codificadores, todas as ferramentas são integradas à GUI, o que permite que eles projetem, compilem e depurem o kernel. Por outro lado, as opções de linha de comando são para usuários convencionais.
- GUI/codificador: Não disponível no momento
- Opção de linha de comando:
Aqui estão alguns comandos úteis para desenvolvedores de kernel:
kernel.cl -o bin/kernel.aocx –board=<board_name>
- Compila kernel.cl arquivo-fonte em um arquivo de programação FPGA (kernel.aocx) para placa especificada pelo <board_name>; -o é usado para especificar o nome e a localização do arquivo de saída
aoc kernel.cl -o bin/kernel.aocx –board=<board_name> -march=emulador
- Cria um arquivo aocx para emulação que pode ser usado para testar a funcionalidade do kernel
aoc -list-boards
- Exibe uma lista de placas e saídas disponíveis
aoc -help
- Exibe a lista completa de opções de comando aoc e informações de ajuda para cada uma dessas opções
versão aocl
- Mostra informações sobre a versão instalada do Intel FPGA SDK para OpenCL
instalação aocl
- Instala drivers para a sua placa no sistema host atual
diagnóstico de aocl
- Executa o programa de teste do fornecedor da placa
programa aocl
- Configura uma nova imagem FPGA na placa
flash aocl
- Inicializa o FPGA com uma configuração de inicialização especificada
ajuda aocl
- Exibe a lista completa de opções de comando aocl e informações de ajuda para cada uma dessas opções
Especificação do OpenCL
Compatibilidade de Khronos
Intel® FPGA SDK para OpenCL™ é baseado em uma especificação publicada de Khronos e é apoiado por muitos fornecedores que fazem parte do grupo Khronos. Intel FPGA SDK para OpenCL passou pelo processo de teste de conformidade de Khronos. Ela está em conformidade com o padrão OpenCL 1.0 e oferece os cabeçalhos OpenCL 1.0 e OpenCL 2.0 do Grupo Khronos.
Atenção: O SDK atualmente não é compatível com todas as interfaces de programação de aplicativos (APIs) OpenCL 2.0. Se você usar os cabeçalhos OpenCL 2.0 e fizer uma chamada para uma API não suportada, a chamada retornará um código de erro para indicar que a API não é totalmente suportada.
O Intel FPGA SDK para o tempo de execução do host OpenCL está em conformidade com a camada de plataforma OpenCL e a API com alguns esclarecimentos e exceções, que podem ser encontrados na seção Statuss de suporte de recursos OpenCL do Intel FPGA SDK para guia de programação OpenCL.
Outros links relacionados:
- Para obter mais informações sobre o OpenCL, acesse a página Kronos Group OpenCL Overview .
- O status atual de conformidade pode ser encontrado na página do Programa Kronos Group Adopter .
- Para mais informações sobre o padrão OpenCL 1.0, consulte a Especificação do OpenCL pela Khronos.
Extensões OpenCL
Canais (E/S ou Kernel)
O SDK Intel® FPGA para extensão de canal OpenCL™ fornece um mecanismo para transmitir dados para kernels e sincronizar kernels com alta eficiência e baixa latência. Use os seguintes links para obter mais informações sobre como implementar, usar e imitar canais:
- Implementando o Intel FPGA SDK for OpenCL Channels Extension
- Usando canais com cópias do Kernel
- Relatório HTML: Conceitos de projeto do Kernel - Canais
- Transferir dados por meio do Intel FPGA SDK para canais OpenCL ou tubos OpenCL
- Requisito para múltiplas filas de comando em canais ou implementação de tubos
Nota: se você quiser aproveitar os recursos dos canais, mas tiver a capacidade de executar seu programa de kernel usando outros SDKs, implemente tubulações OpenCL. Para obter mais informações sobre tubulações, consulte a seguinte seção sobre tubulações.
Tubos
Intel FPGA SDK para OpenCL oferece suporte preliminar para funções de pipe OpenCL, que fazem parte da especificação OpenCL versão 2.0. Eles fornecem um mecanismo para transmitir dados para kernels e sincronizar kernels com alta eficiência e baixa latência.
O Intel FPGA SDK para implementação de tubos OpenCL não está totalmente em conformidade com a especificação de OpenCL versão 2.0. O objetivo da implementação da tubulação do SDK é fornecer uma solução que funcione perfeitamente em um dispositivo diferente de conformidade com o OpenCL 2.0. Para habilitar tubos para Intel FPGA produtos, seu projeto deve atender a determinados requisitos.
Consulte os seguintes links para obter mais informações sobre como implementar tubulações OpenCL:
- Implementando Tubos OpenCL
- Transferir dados por meio do Intel FPGA SDK para canais OpenCL ou tubos OpenCL
- Requisito para múltiplas filas de comando em canais ou implementação de tubos
Emulador
Em um fluxo de projeto multistep, você pode avaliar a funcionalidade do seu kernel OpenCL™ executando-o em um ou vários dispositivos de emulação em um host x86-64 Windows* ou Linux*. A compilação do projeto para emulação leva segundos para gerar um arquivo .aocx e permite iterar em seu projeto com mais eficiência sem precisar passar pelas longas horas necessárias para a compilação completa.
Para sistemas Linux, o emulador oferece suporte simbólico de depuração. A depuração simbólica permite localizar as origens de erros funcionais no seu código do kernel.
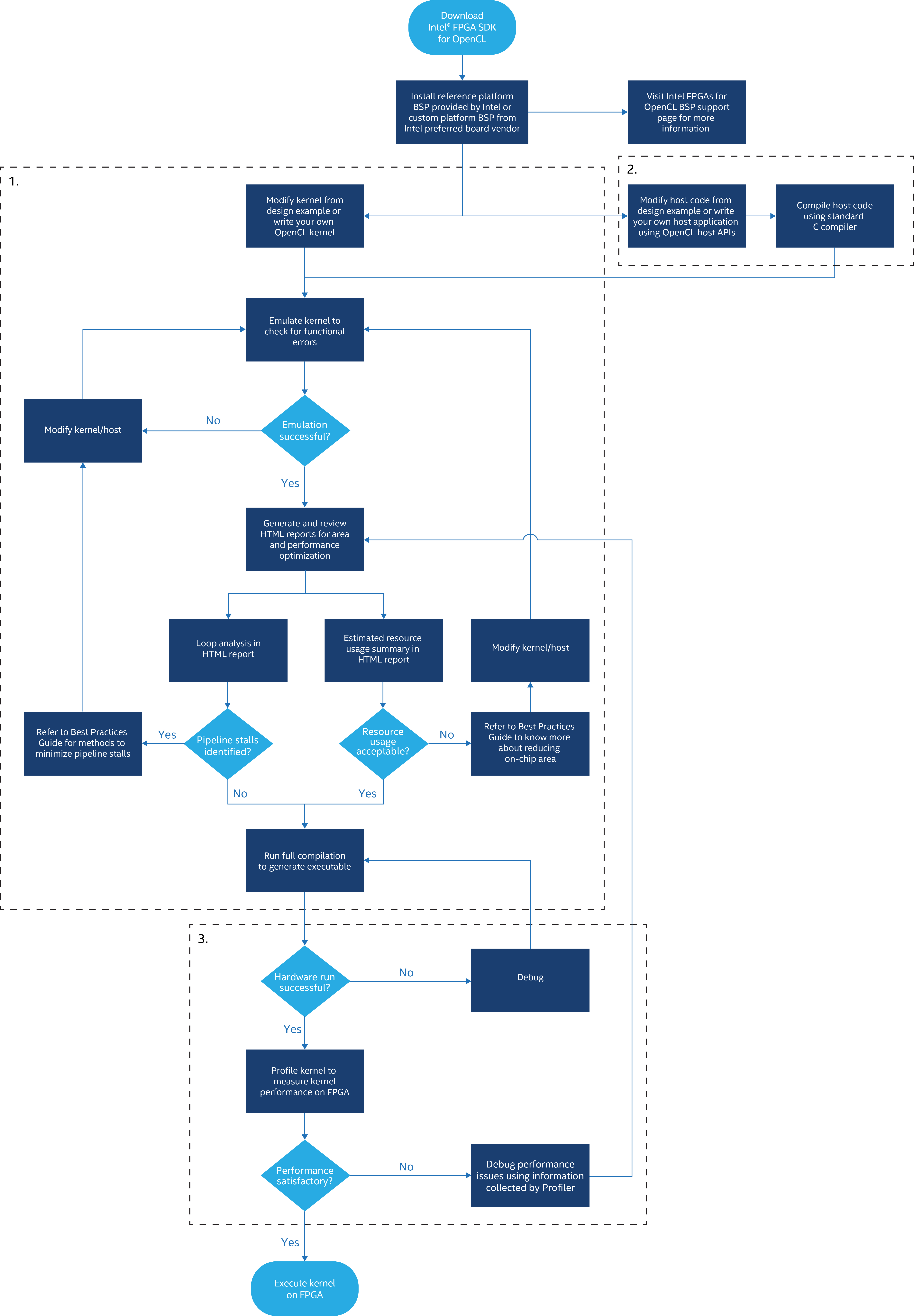
O link abaixo tem uma visão geral do fluxo de projeto para kernels OpenCL e ilustra os diferentes estágios para os quais você pode imitar seu kernel.
SDK multistep Intel® FPGA para fluxo de projeto OpenCL
A seção Emulando e Depurando seu Kernel OpenCL no Guia de Programação contém mais detalhes sobre as diferenças entre a operação do kernel no hardware e a emulação.
Outros links relacionados:
- Emulando e depurando seu kernel OpenCL
- Simulando canais de E/S
- Verificando a funcionalidade de tempo de execução do host via emulação (Windows)
- Verificando a funcionalidade de tempo de execução do host via emulação (Linux)
Otimização
Com o SDK Intel® FPGA para a tecnologia de compilador offline OpenCL™, você não precisa alterar seu kernel para ajustá-lo de forma ideal em uma arquitetura de hardware fixa. Em vez disso, o compilador off-line personaliza a arquitetura de hardware automaticamente para acomodar seus requisitos de kernel.
Em geral, você deve otimizar um kernel que visa primeiro uma única unidade de computação. Depois de otimizar esta unidade de computação, aumente o desempenho escalando o hardware para preencher o restante do FPGA. A pegada do hardware do kernel se correlaciona com o tempo necessário para a compilação de hardware. Portanto, quanto mais otimizações você pode executar com um espaço menor (ou seja, uma única unidade de computação), mais compilações de hardware você pode realizar em um determinado espaço de tempo.
Otimização openCL para FPGAs Intel
Para otimizar a implementação do seu projeto e obter o desempenho máximo, compreenda seu desempenho máximo teórico e compreenda quais são suas limitações. Siga estas etapas:
- Comece com uma implementação funcional simples e boa conhecida.
- Use um emulador para validar a funcionalidade.
- Remova ou minimize as paralisações de gasodutos que são relatadas com o relatório de otimização.
- Planeje o acesso à memória para uma largura de banda de memória ideal.
- Use um perfilador para depurar problemas de desempenho.
O Profiler oferece mais informações sobre o desempenho do sistema, o que oferece direção para otimizar ainda mais o algoritmo no uso da memória.
Lembre-se de que, para FPGAs, mais recursos podem ser alocados, mais financiamento, paralelização e maior desempenho podem ser alcançados.
Relatórios e recursos úteis para otimização
Há uma série de relatórios gerados pelo sistema disponíveis para os usuários. Esses relatórios dão informações sobre o código, o uso de recursos e sugerem onde se concentrar para melhorar ainda mais o desempenho:
- Relatório de análise de loop de um exemplo de projeto OpenCL
- Verificando informações sobre replicação de memória e travamentos
- Informações da área de revisão
- Relatório HTML: Mensagens de relatório de área
Otimização de memória
Entender os sistemas de memória é crucial para implementar uma aplicação usando o OpenCL de forma eficiente.
Interconexão global de memória
Diferentemente de uma GPU, uma FPGA pode construir qualquer unidade de armazenamento de carga (LSU) personalizada que seja a melhor opção para sua aplicação. Como resultado, sua capacidade de escrever código OpenCL que seleciona os tipos de LSU ideais para sua aplicação pode ajudar a melhorar significativamente o desempenho do seu projeto.
Para mais informações, consulte a seção Global Memory Interconnect do Intel FPGA SDK para o guia de melhores práticas do OpenCL.
Memória local
A memória local é um sistema complexo. Ao contrário da arquitetura típica da GPU, onde há diferentes níveis de caches, uma FPGA implementa memória local em blocos de memória dedicados dentro da FPGA. Para mais informações, consulte a seção Memória Local do guia de melhores práticas do Intel FPGA SDK for OpenCL.
Há várias maneiras pelas quais a memória pode ser otimizada para melhorar o desempenho geral. Para obter mais informações sobre algumas das principais técnicas, consulte a seção Allocating Aligned Memory (Alocar memória alinhada ) do Guia de melhores práticas do Intel FPGA SDK para OpenCL.
Para obter mais informações sobre as estratégias para melhorar a eficiência do acesso à memória, consulte a seção Estratégias para melhorar a eficiência do acesso à memória do Guia de melhores práticas do Intel FPGA SDK para OpenCL.
Pipelines
Entender os pipelines é crucial para aproveitar o melhor desempenho de sua implementação. O uso eficiente de pipelines melhora diretamente o desempenho da taxa de transferência. Para mais detalhes, consulte a seção Pipelines do guia de melhores práticas do Intel FPGA SDK for OpenCL.
Para obter mais informações sobre a transferência de dados, consulte os Dados de transferência por meio do Intel FPGA SDK para canais OpenCL ou a seção OpenCL Pipes do guia de melhores práticas do Intel FPGA SDK para OpenCL.
Trava, ocupação, largura de banda
Faça um perfil do seu kernel para identificar gargalos de desempenho. Para mais informações sobre como as informações de criação de perfil ajudam você a identificar comportamentos ruins de memória ou de canal que levam a desempenho de kernel insatisfatório, consulte a seção Criando o perfil do kernel para identificar gargalos de desempenho do Intel FPGA SDK para o Guia de melhores práticas do OpenCL.
Otimização de loop
Algumas técnicas para otimizar os loops são:
Para algumas dicas sobre a remoção de dependências realizadas em loop em vários cenários para um único kernel de item de trabalho, consulte a seção Remover dependência realizada pelo Loop do Intel FPGA SDK para o Guia de Melhores Práticas do OpenCL.
Para mais informações sobre a otimização de operações de ponto flutuante, consulte a seção Otimizando operações de ponto flutuante do Guia de melhores práticas do Intel FPGA SDK para OpenCL.
Otimização de área
O uso da área é uma consideração importante de design se seus kernels OpenCL forem executáveis em FPGAs de tamanhos diferentes. Ao projetar seu aplicativo OpenCL, a Intel recomenda que você siga certas estratégias de projeto para otimizar o uso da área de hardware.
A otimização do desempenho do kernel geralmente requer recursos adicionais de FPGA. Em contraste, a otimização da área muitas vezes resulta em diminuição do desempenho. Durante a otimização do kernel, a Intel recomenda que você execute várias versões do kernel na FPGA board para determinar a estratégia de programação do kernel que gera o melhor tamanho em comparação com a negociação de desempenho.
Para obter mais informações sobre estratégias para otimizar o uso da área FPGA, consulte as Estratégias para otimizar o uso da área de FPGA do guia de melhores práticas do Intel FPGA SDK para OpenCL.
Exemplos de design de referência
Alguns exemplos de projeto que ilustram as técnicas de otimização são os seguintes:
Exemplo de projeto de multiplicação de matriz
Este exemplo mostra a otimização da operação de multiplicação de matriz fundamental usando tiling em loop para aproveitar a reutilização de dados inerente na computação.
Este exemplo ilustra:
- Otimizações de ponto flutuante de precisão simples
- Buffer de memória local
- Compile otimizações (desfinanciamento em loop, atributo num_simd_work_items)
- Otimizações de ponto flutuante
- Execução múltipla de dispositivos
Exemplo de projeto de filtro FIR de domínio tempo
Este exemplo de projeto implementa o parâmetro de referência de filtro de resposta ao impulso finito de domínio do tempo (FIR) do HPEC Challenge Benchmark Suite.
Este design é um ótimo exemplo de como FPGAs pode oferecer desempenho muito melhor do que uma arquitetura de GPU para filtros FIR de ponto flutuante.
Este exemplo ilustra:
- Otimizações de ponto flutuante de precisão simples
- Implementação eficiente de buffer de janela deslizante em 1D
- Métodos de otimização de kernel de item de trabalho único
Exemplo de projeto de downscaling de vídeo
Este exemplo de projeto implementa um downscaler de vídeo que leva vídeo de entrada e saídas de vídeo a 1080p a 110 quadros por segundo. Este exemplo usa vários kernels para ler e escrever com eficiência para a memória global.
Este exemplo ilustra
- Canais de kernel
- Vários kernels simultâneos
- Canais de kernel para kernel
- Padrão de design de janela deslizante
- Otimizações de padrões de acesso à memória
Exemplo de projeto de fluxo óptico
Este exemplo de projeto é uma implementação openCL do algoritmo de fluxo óptico Lucas Kanade. Uma versão densa, não iterativa e não pirâmide com um tamanho de janela de 52x52 é mostrada para executar a mais de 80 quadros por segundo no Kit de desenvolvimento SoC Cyclone® V.
Este exemplo ilustra:
- Kernel de item único de trabalho
- Padrão de design de janela deslizante
- Técnicas de redução do uso de recursos
- Saída visual
Treinamento
O treinamento on-line específico para otimização do OpenCL com exemplos de projeto está disponível em:
- Técnicas de otimização do OpenCL: exemplo de algoritmo de processamento de imagem
- Técnicas de otimização de OpenCL: exemplo de algoritmo de Hash seguro
Referências
Perfil
Em um fluxo de projeto multistep, se o desempenho estimado do kernel da emulação for aceitável, você pode optar por coletar informações sobre como seu projeto funciona enquanto executa na FPGA.
Você pode instruir o SDK Intel® FPGA para o Compilador Offline OpenCL™ para contadores de desempenho de instrumentos no código Verilog no arquivo .aocx com a opção -profile. Durante a execução, o Intel FPGA SDK para OpenCL Profiler mede e relata os dados de desempenho coletados durante a execução do kernel do OpenCL na FPGA. Você pode então analisar os dados de desempenho na GUI do Profiler.
A seção "Criando o perfil do kernel OpenCL " do guia de programação Intel FPGA SDK para OpenCL contém mais informações sobre como criar um perfil do seu kernel.
Como analisar dados de criação de perfil
As informações de criação de perfil ajudam a identificar comportamentos ruins de memória ou de canal que levam a desempenho insatisfatório do kernel. O perfil seu Kernel para identificar gargalos de desempenho da seção Intel FPGA SDK para o Guia de melhores práticas do OpenCL contém informações mais detalhadas sobre a GUI do Dynamic Profiler e como interpretar dados de perfil, como paralisação, largura de banda, hits de cache, e assim por diante. Ele também contém a análise do Profiler de vários cenários de exemplo de projeto OpenCL.
2. Desenvolvedor de código de host
Bibliotecas host em tempo de execução
O Intel® FPGA SDK para OpenCL™ oferece um compilador e ferramentas para você criar e executar aplicativos OpenCL destinados Intel FPGA produtos.
Se você precisar apenas do SDK Intel FPGA para a funcionalidade de implantação de kernel do OpenCL, baixe e instale o Intel FPGA Runtime Environment (RTE) para OpenCL.
O RTE é um subconjunto do Intel FPGA SDK para OpenCL. Ao contrário do SDK, que oferece um ambiente que permite o desenvolvimento e a implantação de programas de kernel OpenCL, o RTE oferece ferramentas e componentes de tempo de execução que permitem criar e executar um programa host, e executar programas de kernel OpenCL pré-compatíveis em placas aceleradoras alvo.
Não instale o SDK e o RTE no mesmo sistema host. O SDK já contém o RTE.
Utilitários e bibliotecas de tempo de execução de host
O RTE para OpenCL oferece utilitários, bibliotecas de tempo de execução do host, drivers e bibliotecas e arquivos específicos de RTE.
- O Utilitário RTE inclui comandos que você pode invocar para executar tarefas de alto nível. Os utilitários RTE são um subconjunto dos utilitários SDK Intel FPGA para OpenCL
- O host runtime oferece a API da plataforma de host OpenCL e a API de tempo de execução para seu aplicativo host OpenCL.
O tempo de execução do host consiste nas seguintes bibliotecas:
- Bibliotecas estaticamente vinculadas oferecem APIs de host do OpenCL, abstrações de hardware e bibliotecas de ajuda
- Bibliotecas de link dinâmico (DLLs) oferecem abstrações de hardware e bibliotecas de ajuda
Para obter mais informações sobre utilitários e bibliotecas de tempo de execução de host, consulte o Conteúdo da seção RTE Intel FPGA para OpenCL do Guia de introdução Intel FPGA RTE para OpenCL.
Transmissão de dados (canal de host)
Agora você pode reduzir significativamente a latência do sistema de seus sistemas usando canais host que permitem que os dados de transmissão do host transmitam diretamente para o kernel do FPGA por meio da interface PCIe* enquanto contornam o controlador de memória. O kernel FPGA pode começar a processar os dados imediatamente e não precisa esperar a conclusão da transferência de dados. Os canais de host são suportados nas interfaces de programação de aplicativos (APIs) de tempo de execução OpenCL e incluem suporte para emulação.
Para obter mais detalhes sobre canais de host e suporte de emulação, consulte a seção Emulando canais de E/S do guia de programação Intel® FPGA SDK para OpenCL™.
Criando o perfil
Criar perfis permite que você saiba onde seu programa passou seu tempo e quais são as diferentes funções chamadas. Essas informações mostram qual parte do seu programa está em execução mais lenta do que você esperava, que poderia precisar de uma reescrita para uma execução mais rápida do programa. Ele também pode dizer quais funções estão sendo chamadas com mais ou menos frequência do que você esperava.
gprof
O gprof é uma ferramenta de código aberto disponível nos sistemas operacionais Linux* para criar o perfil do código-fonte. Ele funciona com amostragem baseada no tempo. Durante intervalos, o contador do programa é interrogado para decidir em que ponto no código a execução chegou.
Para usar o gprof, recompila o código-fonte usando a bandeira de criação de perfil do compilador -pg
Execute os executáveis para gerar os arquivos contendo informações de perfil:
Um arquivo específico chamado "gmon.out" contendo todas as informações que a ferramenta gprof requer para produzir dados de criação de perfil legíveis é gerado. Portanto, agora use a ferramenta gprof da seguinte maneira:
$ gprof código-fonte gmon.out > profile_data.txt
profile_data.txt é o arquivo que contém as informações que a ferramenta gprof usa para produzir dados de criação de perfil legíveis pelo homem. Isso contém duas peças: perfil plano e chamada gráfico.
O perfil plano mostra quanto tempo seu programa passou em cada função e quantas vezes essa função foi chamada.
O gráfico de chamada mostra, para cada função, que funciona chamada, que outras funções chamou, e quantas vezes. Há também uma estimativa de quanto tempo foi gasto nas sub-rotinas de cada função.
Mais informações sobre o uso do gprof para criação de perfil estão disponíveis no site da GNU.
Amplificador VTune™ Intel®
O Amplificador VTune™ Intel® usado para criação de perfil ajuda você a acelerar e otimizar a execução do seu código em plataformas embarcadas Linux, Android* ou sistemas Windows* oferecendo os seguintes tipos de análise:
- Análise de desempenho: Encontre gargalos de código serial e paralelo, analise as escolhas de algoritmo e o uso do mecanismo da GPU e compreenda onde e como sua aplicação pode se beneficiar dos recursos de hardware disponíveis
- Intel Energy Profiler análise: Analise eventos de energia e identifique aqueles que desperdiçam energia
Para mais informações sobre o Amplificador Intel V-tune, acesse Getting Started with Intel VTune Amplifier 2018 for Linux OS website.
Multithreading
A multithread em pipeline OpenCL™ oferece uma estrutura para alcançar uma alta taxa de transferência para algoritmos onde um grande número de dados de entrada precisa ser processado e o processo para cada dados precisa ser feito em ordem sequencial. Uma das melhores aplicações deste framework está em plataformas heterogêneas em que hardware ou plataforma de alta taxa de transferência são usados para acelerar a parte mais demorada da aplicação. Partes restantes do algoritmo devem ser executadas em uma ordem sequencial em outras plataformas, como CPUs, para preparar os dados de entrada para a tarefa acelerada ou usar a saída dessa tarefa para preparar a saída final. Neste cenário, embora o desempenho do algoritmo seja parcialmente acelerado, a taxa de transferência total do sistema é muito menor devido à natureza sequencial do algoritmo original.
Neste AN 831: Intel FPGA SDK para aplicação multithread em pipeline OpenCL, uma nova estrutura em pipeline para projeto de alta taxa de transferência é proposta. Essa estrutura é ideal para processar grandes dados de entrada por meio de algoritmos nos quais a dependência de dados força a execução sequencial de todos os estágios ou tarefas do algoritmo.
FPGA initiailização do host
FPGAs são altamente usadas no espaço de aceleração. O OpenCL tem uma maneira específica de ser usado pela CPU para descarregar tarefas para FPGA. O arquivo anexado abaixo contém as etapas de inicialização comuns necessárias para o código host iniciar o kernel FPGA. Faça download do arquivo contendo as etapas de inicialização aqui.
A função init() pode ser chamada da função() principal() para inicializar a FPGA. O código encontra primeiro o dispositivo no qual o kernel será executado e, em seguida, programa-o com o aocx fornecido no mesmo diretório que o host execuatável. Após as etapas de inicialização no código, o usuário deve definir os argumentos do kernel de acordo com as necessidades de seus projetos.
Há também uma função de limpeza() que libera os recursos após a execução do kernel.
3. Depuração
Emulação
O Intel® FPGA SDK for OpenCL™ Emulator pode ser usado para verificar a funcionalidade do kernel. O usuário também pode depurar a funcionalidade do kernel OpenCL como parte do aplicativo host em sistemas Linux*. O recurso de depuração fornecido com o Intel FPGA SDK for OpenCL Emulator permite que você o faça.
Para mais informações, consulte estas seções no guia de programação Intel FPGA SDK for OpenCL:
Perfil
Para mais informações sobre o perfil, consulte estas seções no guia de programação Intel® FPGA SDK for OpenCL™:
Variáveis de depuração em tempo de execução |
|
|---|---|
| Existem determinadas variáveis de ambiente que podem ser configuradas para obter mais informações de depuração durante a execução do aplicativo host. Essas são Intel® FPGA SDK para variáveis de ambiente específicas do OpenCL™, que podem ajudar a diagnosticar problemas com projetos personalizados de plataforma. A tabela a seguir lista todas essas variáveis de ambiente, bem como as descreve em detalhes. | |
| Título de variável do ambiente | Descrição |
ACL_HAL_DEBUG |
Defina essa variável para um valor de 1 a 5 para aumentar a saída de depuração da camada de abstração de hardware (HAL), que faz interface diretamente com a camada MMD. |
ACL_PCIE_DEBUG |
Defina esta variável para um valor de 1 a 10.000 para aumentar a saída de depuração a partir do MMD. Essa configuração variável é útil para confirmar que o registro de ID da versão foi lido corretamente e os núcleos de IP UniPHY são calibrados. |
ACL_PCIE_JTAG_CABLE |
Defina essa variável para substituir o argumento quartus_pgm padrão que especifica o número do cabo. O padrão é o cabo 1. Se houver vários cabos de download Intel® FPGA, você pode especificar um cabo específico definindo esta variável. |
ACL_PCIE_JTAG_DEVICE_INDEX |
Defina essa variável para substituir o argumento quartus_pgm padrão que especifica o índice de dispositivos FPGA. Por padrão, essa variável tem um valor de 1. Se o FPGA não for o primeiro dispositivo na cadeia JTAG, você poderá personalizar o valor. |
ACL_PCIE_USE_JTAG_PROGRAMMING |
Defina essa variável para forçar o MMD a reprogramar a FPGA usando o cabo JTAG em vez de reconfiguração parcial. |
ACL_PCIE_DMA_USE_MSI |
Defina essa variável se desejar usar a MSI para transferências diretas de acesso à memória (DMA) no sistema operacional Windows*. |
Ferramenta de diagnóstico para SDK Intel® FPGA para OpenCL™
A ferramenta de diagnóstico para SDK Intel FPGA para OpenCL ajuda a diagnosticar e resolver vários problemas de instalação/instalação, problemas de hardware e software que aparecem enquanto trabalham com o SDK Intel FPGA para OpenCL. A ferramenta realiza testes de instalação, testes de dispositivos e testes de link. Para obter mais informações sobre a ferramenta, consulte esta apresentação. Para usar a ferramenta, faça o download a partir daqui.
Outras técnicas de depuração
Devido a um loop no programa host, os usuários podem experimentar o sistema OpenCL™ diminuindo a velocidade durante a execução. Para saber mais detalhes sobre tal cenário, consulte a seção Depuração do seu sistema OpenCL que está diminuindo gradualmente a seção do guia de programação do Intel® FPGA SDK para OpenCL.
O Intel Code Builder para OpenCL é uma ferramenta de desenvolvimento de software disponível como parte do Intel FPGA SDK para OpenCL. Ele oferece um conjunto de plug-ins Microsoft* Visual Studio e Eclipse que habilitam recursos para criação, criação, depuração e análise de aplicativos Windows* e Linux* acelerados com OpenCL. Para mais informações, consulte a seção Desenvolvimento/Depuração de Aplicativos OpenCL usando a seção Intel Code Builder for OpenCL do Guia de programação Intel FPGA SDK para OpenCL.
Solução de banco de dados de conhecimento
Intel® Arria® 10 dispositivos
Intel® Stratix® 10 dispositivos
Recursos adicionais
Aqui estão alguns links adicionais da Comunidade Intel FPGA para questões específicas relacionadas ao projeto e às etapas de execução:
4. Treinamento disponível
Treinamentos
Exibir os seguintes cursos de treinamento OpenCL™:
- Introdução à computação paralela com OpenCL™ na Intel® FPGAs
- Escrevendo o OpenCL no FPGAs Intel
- Executando o OpenCL no FPGAs Intel
- Outros cursos de treinamento OpenCL
- Construindo um módulo RTL para o Intel® FPGA SDK for OpenCL™
- Construindo plataformas personalizadas para Intel® FPGA SDK para OpenCL™: fundamentos do BSP
- Construindo plataformas personalizadas para Intel® FPGA SDK para OpenCL™: modificando uma plataforma de referência
Vídeos rápidos do OpenCL™ |
|
|---|---|
Título do vídeo |
Descrição do vídeo |
Este vídeo descreve o procedimento imediato para executar duas aplicações, OpenCL™ HelloWorld e OpenCL Fast Fourier transform (FFT) no SoC Cyclone® V usando uma máquina Windows*. |
|
Como executar Hello World e (outros programas) com OpenCL no SoC Cyclone V usando o Windows Parte 2 |
Este vídeo descreve o procedimento imediato para executar dois aplicativos, OpenCL HelloWorld e OpenCL FFT no SoC Cyclone V usando uma máquina Windows. |
Como executar Hello World e (outros programas) com OpenCL no SoC Cyclone V usando o Windows Parte 3 |
Este vídeo descreve o procedimento imediato para executar dois aplicativos, OpenCL HelloWorld e OpenCL FFT no SoC Cyclone V usando uma máquina Windows. |
Como executar Hello World e (outros programas) com OpenCL no SoC Cyclone V usando o Windows Parte 4 |
Este vídeo descreve o procedimento imediato para executar dois aplicativos, OpenCL HelloWorld e OpenCL FFT no SoC Cyclone V usando uma máquina Windows. |
Como executar Hello World e (outros programas) com OpenCL no SoC Cyclone V usando o Windows Parte 5 |
Este vídeo descreve o procedimento imediato para executar dois aplicativos, OpenCL HelloWorld e OpenCL FFT no SoC Cyclone V usando uma máquina Windows. |
Como empacotar módulos/projetos Verilog personalizados como bibliotecas OpenCL |
O vídeo discute por que os clientes podem potencialmente usar esse recurso para ter seus blocos de processamento personalizados (RTL) no código do kernel OpenCL. O vídeo explica o exemplo do projeto, como os arquivos de makefiles e de configuração, e explica o fluxo da compilação. O vídeo também mostra uma demonstração do exemplo do projeto. |
OpenCL no Altera® SoC FPGA (Host Linux*) — Parte 1 — Download e configuração de ferramentas |
Este vídeo mostra como baixar, instalar e configurar as ferramentas necessárias para desenvolver kernels OpenCL e código de host destinados Altera® SoC FPGAs. |
OpenCL no Altera SoC FPGA (Host Linux) — Parte 2 — Executando o exemplo de vetor Add com o emulador |
Este vídeo mostra como baixar e compilar um exemplo de aplicativo OpenCL destinado ao emulador integrado ao OpenCL. |
Este vídeo mostra como compilar o kernel OpenCL e o código de host destinados ao FPGA e processador do FPGA Cyclone V SoC. |
|
OpenCL no Altera SoC FPGA (Host Linux) — Parte 4 — Configuração do ambiente de tempo de execução |
Este vídeo mostra como configurar a placa SoC Cyclone V para executar o exemplo de OpenCL e executar o código do host e o kernel da placa. |
O conteúdo desta página é uma combinação de tradução humana e por computador do conteúdo original em inglês. Este conteúdo é fornecido para sua conveniência e apenas para informação geral, e não deve ser considerado completo ou exato. Se houver alguma contradição entre a versão em inglês desta página e a tradução, a versão em inglês prevalecerá e será a determinante. Exibir a versão em inglês desta página.